私が作りました(生産者シール)
HOTFIX: v3.0あたりからnpxでインストールすると動作しない状態が2週ほど続いていたようでした。現在はnpxで動作するように修正済みです。ご迷惑おかけしました。
sqlewはもともとClaudeCodeのエージェントが効率的に並列作業をするための、サブエージェント用のコミュニケーションレイヤーを作ったはずでした。
が、使いながら自己開発をするうえで色々な機能が追加・削除されて、今では「プロジェクトのコーディングルールと設計理念を効率的に保持するツール」に落ち着きました。
簡単に紹介
気が短い人向け:
sqlewはAIプログラミング向けのmcpツールです。AI向けプロジェクトのヒストリデータベースを作成し、コンテキストの永続化とトークン効率化を目的にしています。
- RDBMSに記憶を残す(MySQL、PostgreSQL、SQLiteに対応)
- Decisionsとしてコード変更の目的を記録 = WHY
- Constraintsとしてコーディング規約を記録 = HOW
- Tasksとして具体的な作業を記録 = WHAT
カンバン風のタスク管理とファイルウォッチャー連動プラン系のタスク以外ではファイルとの関連付けを必須にしています。関連付けされたファイルが編集された→In Progress最終編集から3分たった→Waiting Reviewgit addされた→donegit commitされた→archived
以下は過去バージョンの機能です。現在は決定方針と誓約のみを保持するシステムに特化しています。
画像は公開していないビジュアライザーですけど、AIがカンバンを使ってタスクオートメーションしているイメージです。
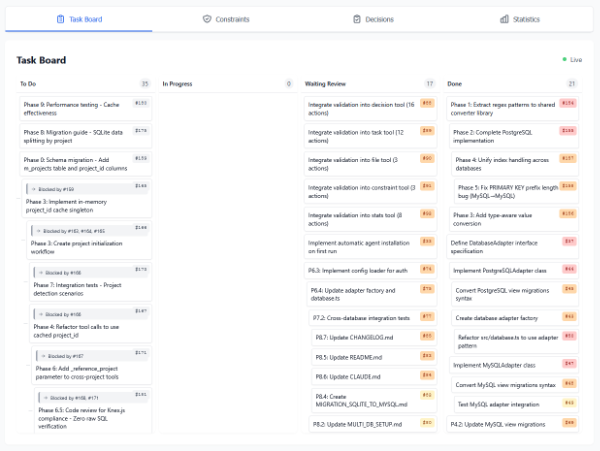
sqlewはnpxコマンド一発で使用可能です。
{
"mcpServers": {
"sqlew": {
"command": "npx",
"args": [
"-y", "sqlew"
]
}
}
}{
"mcpServers": {
"sqlew": {
"command": "cmd",
"args": [
"/c", "npx", "-y", "sqlew"
]
}
}
}sqlewを使うメリット
「コンテキストの永続化」の課題
AIは学習済みモデルデータ以外の”記憶”を持ちません。そのためMarkdownファイルとして”疑似記憶”を作成します。それがCLAUDE.mdだったり.junie/guidelines.mdだったりです。
より詳しくはこちら

眼の前にいるAIは毎回別人
AIは記憶を持たないため、起動するたびにまっさら新しい記憶で作成されます。たとえ前のセッションで濃密な会話をおこなったとしても、次のセッションでは初対面のような扱いを受けます。
Claudeの最近のバージョンでは過去の会話の検索が出来るようになって続きを話しているように見えます。実際は単語をさらっている程度で、過去のコンテキストに対する理解はかなり表面的です。
それだとコーディングでは困るので、上記のような記憶ファイルを作成して、セッションごとに読み込むことで最低限の記憶を残せるようにしています。
AIの忘れっぽさの原因=記憶方式
これらのMarkdownファイルは十分に記憶として機能しますが、プロジェクトが大きくなっていくとこれらのファイルも大きくなります。そしてこれら記憶ファイルを読み込むこと自体がAIにとって負担になり、省略して読み込むようになります。
具体的には
- 禁止と書いている内容を行ってしまう
- 公開済みマイグレーションファイルの変更など
- テスト駆動などのルールを守らない
- 既に実装済みの機能を別な場所に再実装してしまう
- 指定ツールを使わず強引に書き込み
などなど。英文で書いている場合で500行15KB超えくらいからこの傾向が出てきます。
記憶方式を変えることでトラブルを防ぐ
AIの”記憶”はMarkdownファイルなので最低限のテキストではあるんですけれど、自然言語での表現になっているため、AIが読み込むには常にファイル読み込み&全文検索&自然言語解釈が必要になります。AIが読み込める文字量には制限があるため、ある程度の長さで分割し、リンク参照するような工夫も必要になってきます。
こんな感じで、規模が大きくなってくると通常の人間用ドキュメントに加えてAI用のドキュメントも加わるので、なんの説明がどこに書いてあるかを特定するだけでも、AIにも人間にもかなりの負担が発生します。
Serenaのアプローチ
AIコーダーなら必ず入れてるレベルでめちゃくちゃ有名なMCPツールであるSerenaは、ソースコード読み込みでのトークン浪費を防ぐため、既存の構文チェックツールを使って抽象構文木データベースを作ることで解決を図るアプローチをとっています。
AIは特に指示をしないとモノリシックコードを書きがちで、1ファイル2000行60KBとかのコードもよくあります。Serenaはこれらモノリシックコードの中から特定の関数名や変数名で内容を呼び出すことができて、「この関数の後に追記」というツールも備えています。
それのドキュメント版が作れないか?というのがsqlewの開発動機だったりします。
sqlewのインストールと動作原理
お試しで使ってみる場合は面倒な設定が要らないSQLiteでの運用をおすすめします。後からMySQLやPostgreSQLにデータの移行は可能です。
インストール
公式ブログでまとめていますのでこちらの手順でどうぞ。

使い方
初回起動時にプロジェクトルートに.sqlewフォルダが作成されます。この中に設定ファイルconfig.tomlとデータベースファイルsqlew.dbが作成されます。
データベース関連の細かい設定
config.tomlで
- SQLiteデータベースの保存場所を変える
- 既存のデータベースファイルを参照する
- 複数プロジェクトで同一のデータベースを使用する
などもできます。またv3.8以降は任意のIP・ポートのMySQL/MariaDB/PostgreSQLでも動作します。フリーアドレスやリモート環境、グループ開発でも活用出来ると思います。詳しくはGithubのドキュメントを参照ください
プロジェクトIDについて
プロジェクトのIDは、config.tomlに記載がなければpackage.jsonやCargo.tomlなどのパッケージ情報>.gitフォルダ内のレポジトリ名>フォルダ名の順で自動的に設定されます。
コンフィグファイル上では文字列で指定・識別しています。
git worktreeなどで同プロジェクトを分割して作業する場合は同じプロジェクト名にすることで、同一プロジェクトとして認識されます。
基本的にMCPサーバの機能は、AIに明示的に指示をするか、AI自身が強い必要性を感じない限りは使用されません。ClaudeCode環境に限りますが、優先してsqlew機能を使用する専用のカスタムエージェントをデフォルトで追加します。
で、sqlewの効果の程は?
トークン削減効果
Claude Code自身に計測させたので若干眉唾ですが、サブエージェント起動時のトークンが70%くらい削減出来ているらしいです。
根拠としては、
- README.md + ソースコード読み込み : 5~30kトークン
- sqlew Task + Decision + Constraints :1.1kトークン
ということで、モノリシックでクソデカソースコードのプロジェクトには公称値以上に効果絶大かもしれません。
手前味噌ですけど、Claude Code MAX5で並列作業で大規模リファクタリングをやると
- sqlewナシ 1時間で利用制限
- sqlew使用 4時間で利用制限
こんな感じですので、確かにトークン効率は4倍前後=70%程度削減になっているのかもしれません。
手戻りの少なさ
個人的にはこれが大きいかな、と。
Sonnet4.5はなんとなくアンチパターンを学習しちゃってる感じがあります。なのでテキトーにプランニングさせると、過去の失敗例をもう一度やろうとする事があります。
プロジェクトの決定の理由を遡ることができるDecisions、Constraintsはこれらを防ぐことができます。
Aの機能をsqlewエージェントを使ってプランニングしてください毎回エージェント指定をするのがすこしめんどくさいですけど、プランニングではsqlew-architectやsqlew-researcherエージェントが活躍します。
例えば
- Decisions
- #100 〇〇のデザインパターンでAの機能を作成する
- #101 #100の方法では実装不可能とわかったためdevブランチへロールバックした
- Constraints
- #80 デザインパターン〇〇は適合不可
このような履歴があった場合、sqlew-architectは
「〇〇だと失敗するようだ、sqlew-researcherで今の実装と〇〇が適合しなかった理由を突き止めて別なデザインパターンを提案しよう」というような賢い選択をしてくれるようになります。
一言で言うと「記憶の拡張」なんですけど、これはかなり効果あります。
導入直後はあまり恩恵がない
これがSerenaとかと違って「すぐこうです!」と言えない悲しいところなんですけど、使い込んでデータベースを育てる必要があります。しかし育ちきったデータベースは本当に強いです。sqlew自体もsqlewでヒストリデータベースを作成しています。
sqlewは、AIにとってのこういうオッサンをモチーフに作っています。
- 特にバリキャリとかカリスマPGとかではない
- なのに、なにか変更があるときはPMにいつも相談されている
- どういう経緯で今こういう実装になっているのかに詳しい
- ドメイン固有の小ネタ・ノウハウをやたら持っている
- 目立たないけどプロジェクト初期から参画している
sqlewの今後の改善予定
その他、こんな機能がほしいというのがあれば、ここのコメントやIssueで投げてもらえれば対応します!




コメントを残す